

랭크함수를 이용하면 손쉽게 순위를 매길 수 있다.
PATITON BY는 분석함수를 사용할 때 그룹으로 묶어서 연산을 할 수 있게 해 준다.
ROW_NUMBER()와 PARTITION by를 이용해 순위 정하기
select idx,cate1,cnt,rn from(
SELECT idx,cate1,cnt,
ROW_NUMBER() over(PARTITION by cate1 order by cnt desc) as rn
from tt_board
) c where rn < 3랭크함수를 이용해 카테고리별로 cnt가 높은 2개의 데이터만 조회해 봤다.
랭크함수는 여러 가지가 있지만 ROW_NUMBER()만 순위 중복 허용을 하지 않기에 사용했다.
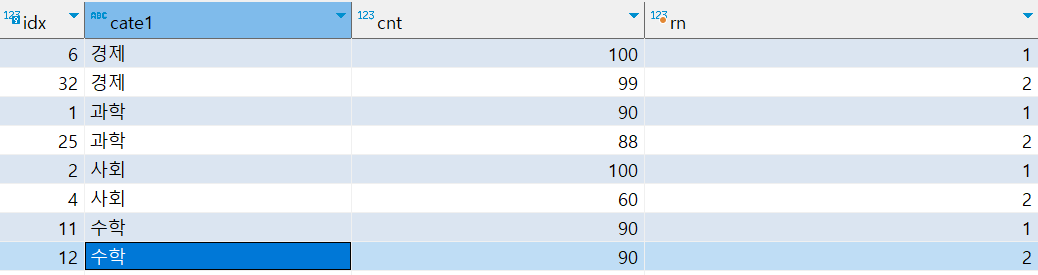
쿼리를 실행해 보면 카테고리별로 cnt가 높은 데이터가 2개씩 조회되는 것을 알 수 있다.
랭크함수의 종류
SELECT idx,cate1,cnt,
ROW_NUMBER() over(PARTITION by cate1 order by cnt desc) as 'ROW_NUMBER',
DENSE_RANK() over(PARTITION by cate1 order by cnt desc) as 'DENSE_RANK',
RANK() over(PARTITION by cate1 order by cnt desc) as 'RANK'
from tt_board예제를 통해 각각의 랭크함수의 다른 점을 확인해보자.
ROW_NUMBER()는 중복값을 허용하지 않고 DENSE_RANK(), RANK()는 중복값을 허용한다.
ROW_NUMBER()는 무조건 순위를 나누지만 DENSE_RANK(),RANK()는 동일점수는 같은 순위로 점수를 매긴다.

또한 DENSE_RANK()와 RANK()의 차이점은 DENSE_RANK()는 같은 순위가 발생하더라도 다음 순위를 적용하지만(1,1,2,2,3,4) RANK()는 같은 순위인 데이터만큼을 건너뛰고 순위를 매긴다(1,1,3,3,5).