robots.txt 설정 방법과 규칙
robots.txt란?
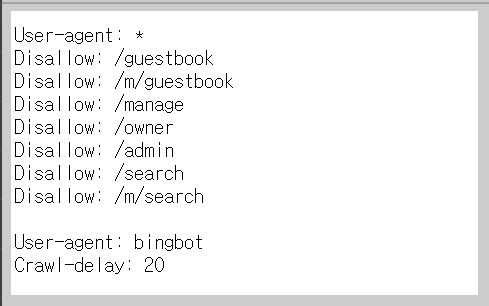
robots.txt란 IETF에서 검색로봇의 웹페이지 수집 허용/제한을 하는 국제 권고안이다.
간단히 말해 검색엔진 크롤러 또는 검색 로봇이 사이트에서 정보수집을 해도 되는 페이지와 해서는 안 되는 페이지를 알려주는 파일을 뜻한다.
일반적인 사이트의 경우 검색엔진 최적화를 위해 여러 가지 봇들의 정보 수집을 허용하지만 때에 따라선 검색되지 말아야 할 페이지를 선언해주기도 한다.
robots.txt 위치
robot.txt 파일은 반드시 사이트 루트 디렉토리에 위치해야 하며 텍스트 파일로 접근이 가능해야 한다.
http://사이트 주소/robots.txt
티스토리의 경우에도 각 블로그마다 루트 디렉터리에 robots.txt 파일이 존재한다.
robots.txt 규칙
1. user-agent : 필수, 규칙이 적용되는 검색엔진 크롤러의 이름을 지정한다.
2. disallow : 크롤링 하지 않도록 하려는 루트 도메인 관련 디렉터리 또는 페이지를 뜻한다.
3. allow : 크롤링 할수 있는 루트 도메인 관련 디렉터리 또는 페이지를 뜻한다.
disallow 규칙을 함께 적용하면 허용된 디렉토리 범위 내에서 크롤링하지 않을 규칙을 재정의 할 수 있다.
4. sitemap : 웹 사이트의 사이트맵 위치를 뜻한다.
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://www.example.com/foo.html</loc>
<lastmod>2022-06-04</lastmod>
</url>
</urlset>가장 흔하게 사용되는 xml 사이트맵 형식을 살펴보면 각 메뉴의 주소를 뜻하는 loc 태그와 수정날짜를 뜻하는 lastmod 태그로 이루어져 있다.
robots.txt 예제
User-agent: *
Allow: /모든 검색엔진의 로봇 수집 허용
User-agent: *
Disallow: /모든 검색엔진의 로봇 수집 비허용
Allow: /$을 함께 기입하면 루트 페이지만 수집을 허용할 수 있다.
User-agent: *
Allow: /
User-agent: Yeti
Disallow: /모든 검색엔진의 로봇 수집을 허용하지만 특정 로봇 엔진의 수집을 비허용
User-agent: *
Allow: /
Disallow: /admin*/관리자페이지나 개인정보페이지는 위와 같이 url을 기입함으로써 수집 비허용 설정을 해줄 수 있다.
User-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xml내 사이트에 있는 페이지들의 목록이 담겨있는 sitemap.xml의 위치를 기입하면 검색로봇이 내 사이트의 페이지들을 더 잘 수집해 가게 할 수 있다.
robots.txt 검증사이트
이렇게 만든 robots.txt 파일은 올바르게 작성이 됐는지 검증이 필요하다.
웹사이트 플라넷 사이트의 VALIDATOR를 이용하면 오타, 구문 및 논리 오류로 인한 오류가 없는지 검증을 하고 보고서를 생성할 수 있다.